Navigation auf uzh.ch
Navigation auf uzh.ch
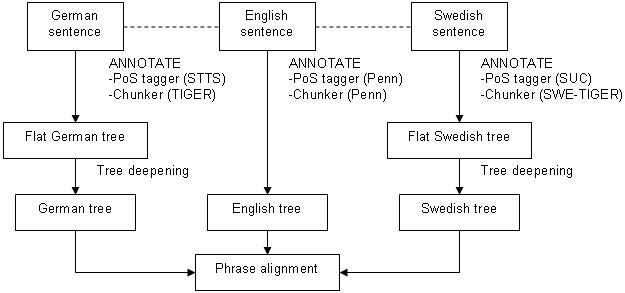
A number of tools have been used in creating the SMULTRON parallel treebank. The pictures show the process of creating the monolingual treebanks and how they are combined into the parallel treebank. (The deepening and lemma merging steps are skipped for the English treebank.)
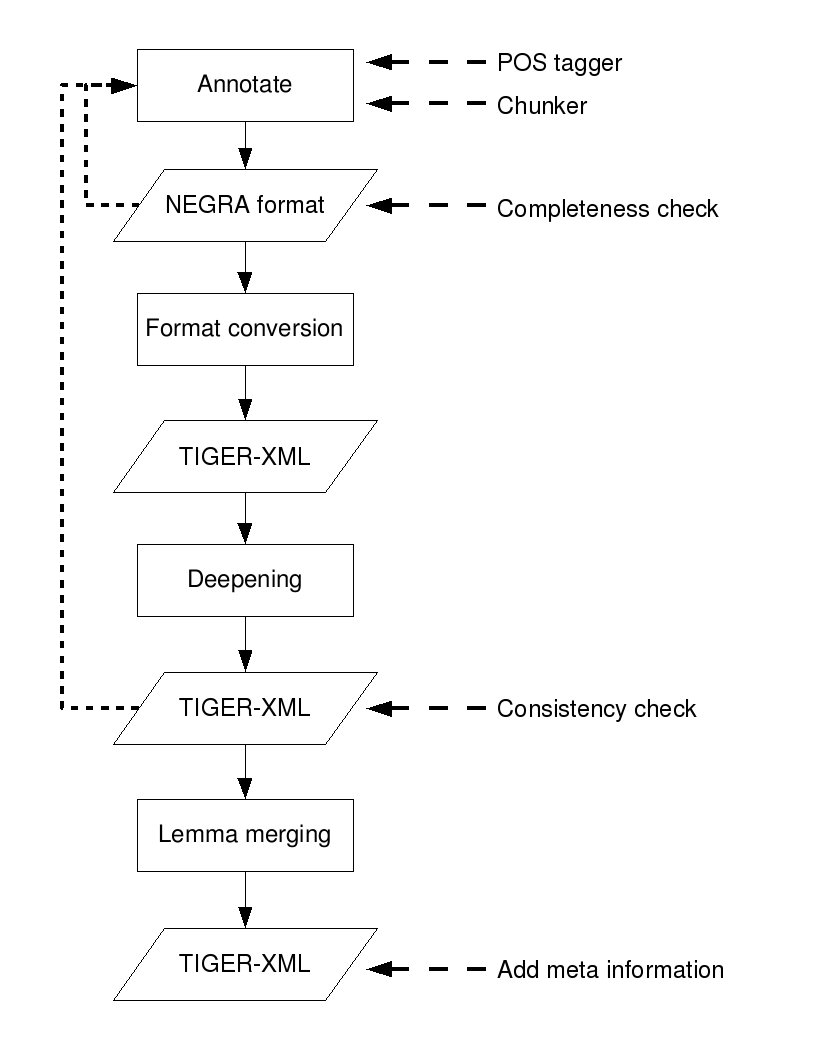
We used the Annotate treebank editor in creating the monolingual treebanks, which allows for semi-automatic annotation. The parser in Annotate is based on the TnT PoS tagger and Cascaded Markov Models, where each layer of the syntactic structure is represented by a Markov Model. It finds all the possible phrases for the first layer and selects the best assumption. If the annotator accepts this hypothesis, all others are deleted, else the rejected hypothesis is deleted. The syntactic structure is then built bottom-up, the parser suggests new nodes based on the already created partial syntactic structure and the PoS tags. The annotator always has the possibility to accept, get a new suggestion or create a new node manually. The parser gives correct suggestions in about 70% of the cases and a trained annotator can expedite about 1300 tokens per hour for PoS and structural annotation in the NEGRA corpus.
Annotate is developed at the University of Saarbrücken, see www.coli.uni-sb.de/sfb378/negra-corpus/annotate.html
The TIGERSearch tool is a search engine for retrieving information from a database of graph structures. It has a graphical user interface and a powerful query language. As a side-effect, it converts the database into Tiger-XML.
TIGERSearch was developed at the University of Stuttgart, see http://www.ims.uni-stuttgart.de/forschung/ressourcen/werkzeuge/tigersearch.html
The TIGER annotation guidelines give a rather flat phrase structure tree. This means for instance no unary nodes, no "unnecessary" NPs (noun phrases) within PPs (prepositional phrases) and no finite VPs (verb phrases). Flat trees have two advantages for manual treebank annotation: the annotator needs to make fewer decisions, and the annotator has a better overview of the trees. This comes at the price of the trees not being complete from a linguistic point of view and it is also problematic for node alignment in a parallel treebank. We prefer to have "deep trees" to be able to draw the alignment on as many levels as possible. Our deepening program (written in Perl) inserts unambiguous nodes into the tree structure.
The script is available upon request.
Completeness and consistency are important characteristics of corpus annotation. Tree completeness means that each token and each node is part of the tree. This can easily be checked and should ideally be part of the annotation tool. Consistency checking over treebanks is a lot more complicated. Consistent annotation means that the same token sequence (or part-of-speech sequence or node sequence) is annotated in the same way across the treebank. Markus Dickinson and Detmar Meurers have proposed various methods to check treebanks for consistency violations. We have used one of their methods for counting how often a sequence has a certain mother node. For example, if the sequence of Determiner - Noun is mostly annotated as a noun phrase, but only a few times as something else, then these few occurrences are possible annotation errors. The method basically extracts all phrase structure rules from the treebank and sorts and counts them by their right-hand sides. This reduces the manual labour and is very useful.
See the DECCA homepage for further information.
The TreeAligner is a graphical user interface to insert (or correct) alignments between pairs of syntax trees. The tool allows you to create links between corresponding nodes (or words) in two treebanks in different languages. It displays trees from input files in Tiger-XML format (one file for each language). The alignment is stored separately in an XML-file. The TreeAligner displays tree pairs with the trees in mirror orientation (one top-up and one top-down).
More information about the TreeAligner.